(TLDW): State of GPT - Andrej Karpathy
Notes from Andrej Karpathy's talk at Microsoft Build

How to train your (Chat)GPT Assistant

Pretraining
Data collection - download a large amount of publicly available data. Such as through webscraping, stack overflow/exchange, wikipediea etc.
Context length = max # of integers that the model will look at to predict the next integer in the sequence
Dont judge a model by the number of parameters it contains.
“Base models are not assistants, they just want to complete documents”
For example - if you ask it to write a poem about bread and cheese, it will just respond with more questions. But if you write “here’s a poem about bread and cheese”: it will autocomplete your document
You can trick base models into assistants with few shot prompting.
Mode Collapse
RLHF vs SFT
RLHF models are ranked higher than SFT
Base models can be better in tasks where you have N example of things and want to generate more N things. Base models = more entropy
Disadvantages: LLM Text generation vs Human
LLMs spend the same amount of compute on every token
They don’t reflect, they don’t sanity check, they don’t correct their mistakes along the way.
Cognitive advantages: LLM vs human
They DO have a very large fact based knowledge across a vast number of areas
They do have a large and ~perfect “working memory” (Context window)
Prompting is making up for this difference between these two architectures: Human brains vs LLM Brains
Chain of thought
“Models need tokens to think” →

“Let’s think step by step”
By snapping into a mode to show its work it will do less computational work per token more likely to succeed because its doing slower reason over time.
Ask for reflection
LLMs can often recognize later when their samples didn’t seem to have worked out well
LLMs can get unlucky in its sampling and a “bad” token but it doesn’t know to go back. LLMs will continue down this bad alley even if there’s no end. You have to ask to see if it met your prompt’s requirement.
Chains / Agents
Think less “one-turn” Q&A and more chains, pipelines, state machines, agents
Condition on Good Performance
LLMs don’t want to succeed. They want to imitate training sets with a spectrum of performance qualities. you want to succeed and you should ask for it.
For example: “Lets think step by step:” is okay
“Let’s work this out in a step by step way to be sure we have the right answer” is better
Tools Use / Plugins
Offload tasks that LLMs are not good at. Importantly: They don’t “know” they are not good.
For example arithmetic → You need to tell it in the prompt that they are not good at arithmetic and ask it to use a tool.
Retrieval-Augmented LLMs
Load related context/information into “working memory” context window
Emerging recipe
Break up relevant documents/data connectors into chunks
Use Embeddings API to index chunks into a vector store
Given a test-time query, retrieve related information
Organize the information into the prompt.
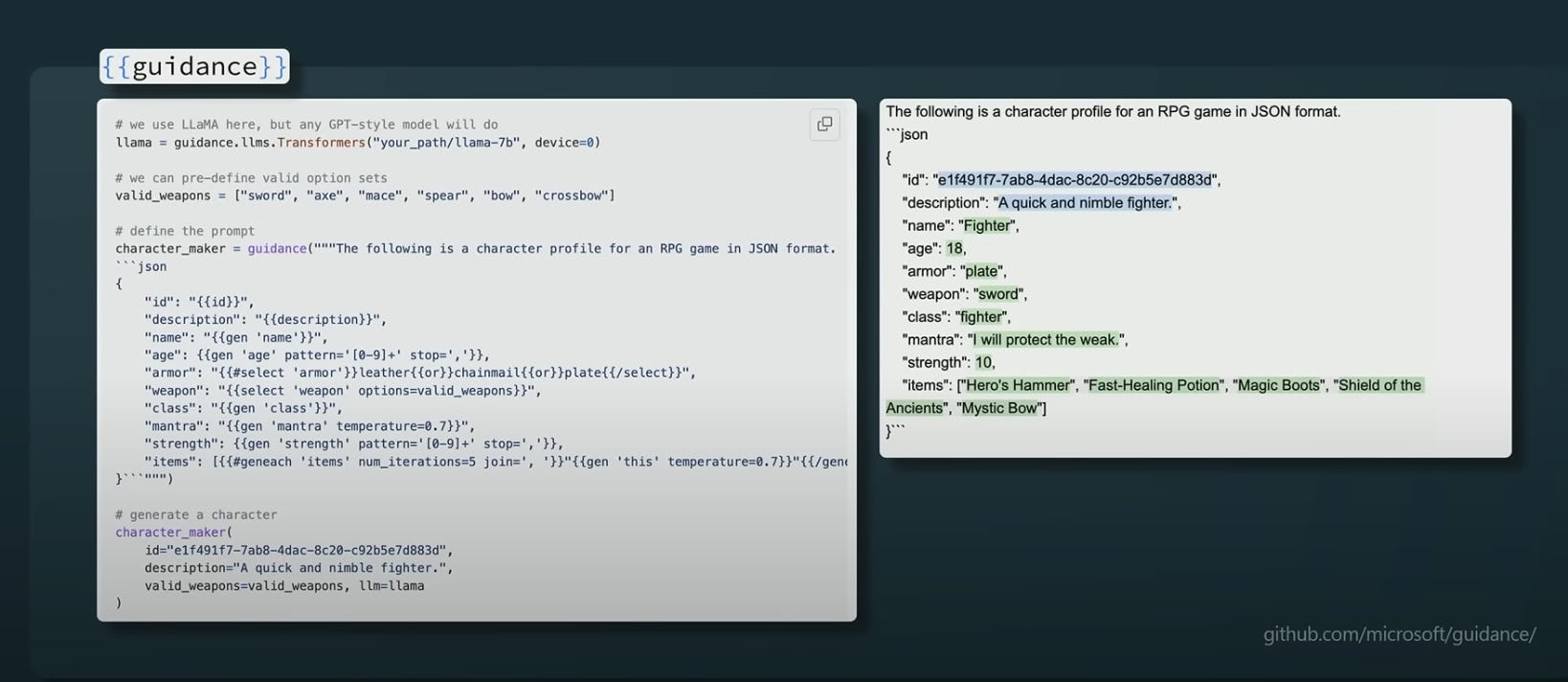
Constrained Prompting
“Prompting languages” that interleave generation, prompting, logical control
Default Recommendations

Other recommendations for Use cases
Use in low-stakes applications, combine with human oversight
Source of inspiration, suggestions
Copilots over autonomous agents